最近在 GitHub 上看到一个非常火的图转代码开源项目(https://github.com/abi/screenshot-to-code) ,star 数量达到了 5万+,结合我自己在做的 UI2Code 项目,探究下它的具体实现方法。
为什么值得学习?
过往在 UI2Code 项目中都是基于设计稿件,通过解析出结构化的 Json 数据,然后来做布局处理,最后转化成代码。这里有一个前提,即需要提供 UI 设计稿,设计稿通常被定义为 figma 稿件 或者 sketch 稿件等。而这个开源项目使用的是静态图片,是无图层信息的位图,那这也是最吸引我的地方。
screentshot-to-code
上传截图自动生成网页 HTML,背后原理是使用 Claude Sonnet 3.5 或 GPT-4o 生成代码,使用 DALL-E 3 生成相似图像。

经过一番摸索测试,发现这个项目生成的效果不太稳定,如果用在业务中看起来不太可行。那么有没有一种更稳定的实现方式呢?
实现路径
先构思下整体流程:
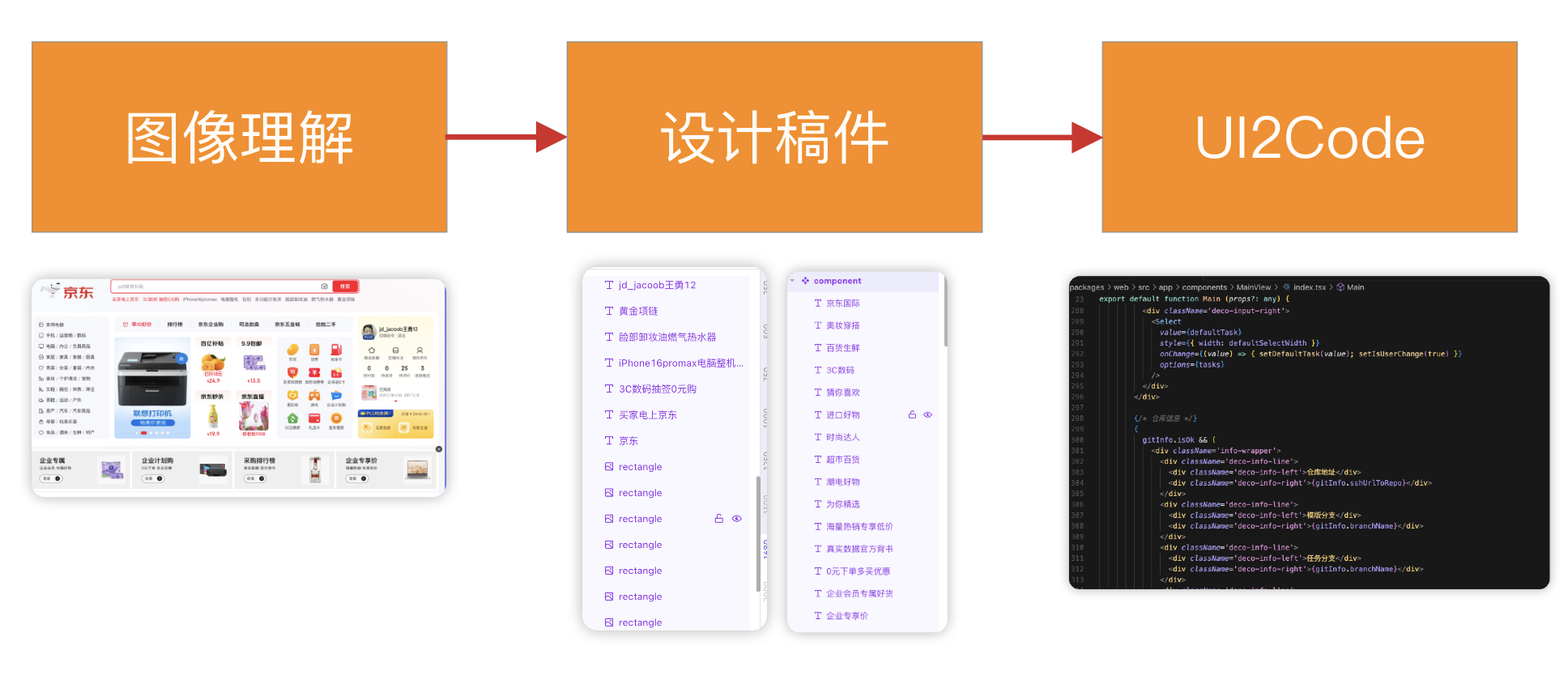
大体而言,跟 UI2Code 流程无太大差异,最大区别还是在第一个步骤:如何将图片转成设计稿件。设计稿件转代码已经是一套现有非常成熟的解决方案。
下面看下如何解决图片转设计稿件。
图转稿件
首先,需要明确下稿件有哪几种数据类型,下面以我们自研的类 figma 工具而言,一个稿件的图层类型如下:
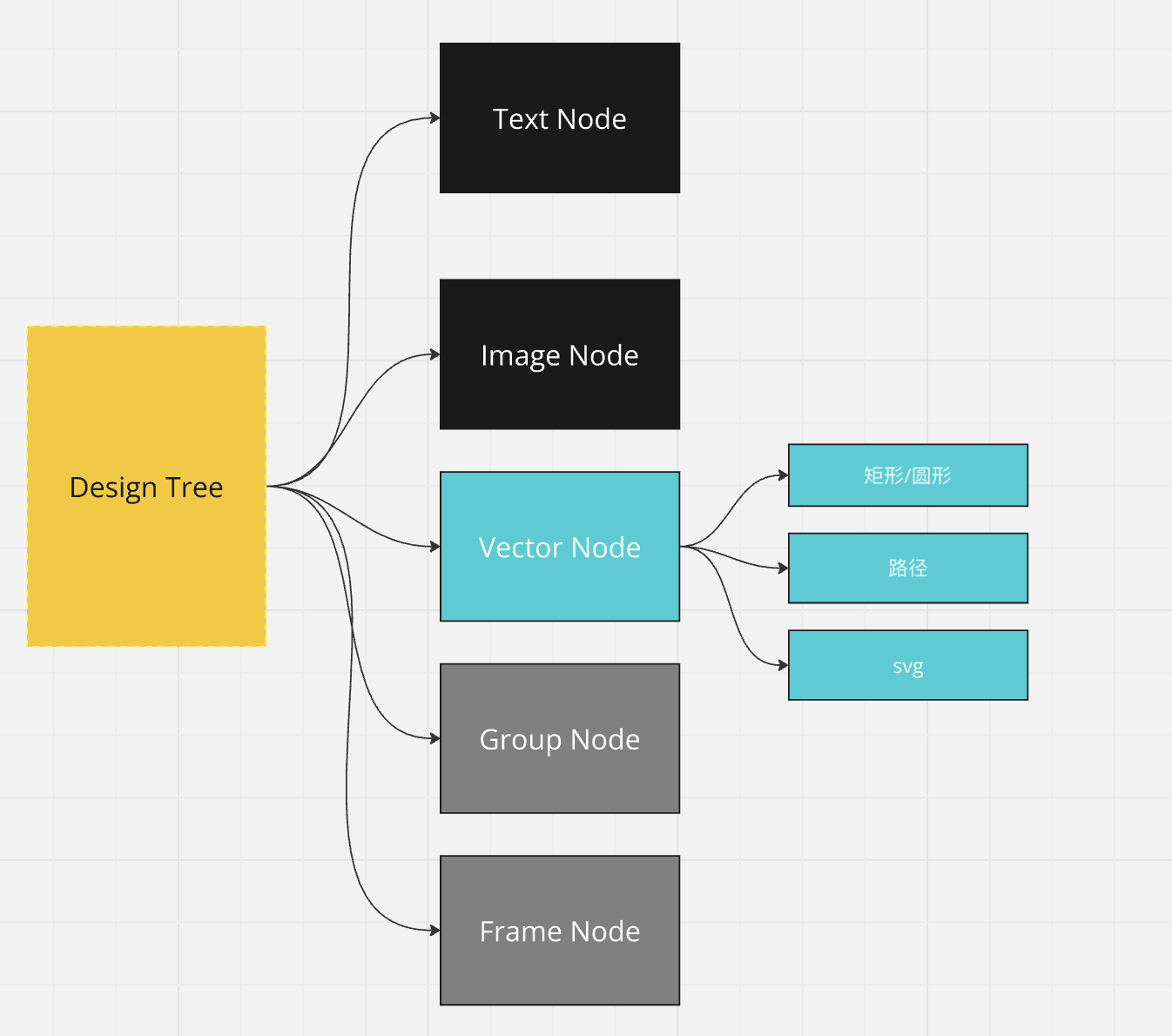
而我们从静态图片中能够提取出来的数据类型有三种:
- 文本类型
文本可以通过 ocr 的方式获取图像上包含的文字信息和文字坐标以及文字的颜色等信息。 - 图像类型
需要去分解一张大图上的各个小图,从而实现图片类型图层的提取。 - 容器类型
容器是一个组,它是若干文本和图像的区块,可以理解把一张图片划分成多个组,前端同学可以理解为我们经常用 div 来包裹若干内容图层。
文本 OCR
OCR 是比较成熟的技术,为了快速验证,选取 https://github.com/PaddlePaddle/PaddleOCR?tab=readme-ov-file 作为方案实现。提取文字内容和文字坐标。
如何提取文字颜色?
通过 OCR 获取文字坐标后,尝试通过 cv 的方式获取文字颜色。
def get_font_color(self, image, text_nodes):
for node in text_nodes:
x0 = node['x']
x1 = node['x'] + node['width']
y0 = node['y']
y1 = node['y'] + node['height']
_img = image[y0:y1, x0:x1]
_gray = cv2.cvtColor(_img, cv2.COLOR_BGR2GRAY)
threshold = np.mean(_gray)
rec, mask_ = cv2.threshold(_gray, threshold, 255, cv2.THRESH_BINARY)
p = len(np.where(mask_ == 255)[0]) / (mask_.shape[0] * mask_.shape[1])
if p < 0.5:
font_value = 255
back_value = 0
else:
font_value = 0
back_value = 255
font_color = np.mean(_img[np.where(mask_ == font_value)], axis=0)
back_color = np.mean(_img[np.where(mask_ == back_value)], axis=0)
node['font_color'] = (int(font_color[0]), int(font_color[1]), int(font_color[2]))
node['bg_color'] = (int(back_color[0]), int(back_color[1]), int(back_color[2]))
print(node)
图像分割
分割则需要用到当下比较流行的 SAM 模型, https://docs.ultralytics.com/zh/models/fast-sam/
容器成组
成组的识别主要基于规则判断,简化识别逻辑。可以基于图像节点与文本节点是否相交重叠,如果存在重叠,考虑使用一个容器来包裹文本和图像。
节点数据类型
{
"type": '',
"content": None,
"style": {
"border": None,
"borderWidth": None,
"borderColor": None,
"backgroundColor": None,
"borderRadius": None,
"color":None,
"fontSize": None
},
"position": {
"x": 0,
"y": 0
},
"size": {
"width": 0,
"height": 0
},
"children": []
}
通过输入一张图片,解析出一个 node[] 即完成了图片转稿件的流程,而后续稿件转代码是固有流程,就不需要再实现了。
因此本文是图转稿件相关的核心技术,当然除了使用算法模型对图像理解之外,也可以结合 LLM 来优化整个流程,但如果用在企业服务中,还是直接使用垂直领域的模型效果更好更稳定。