作为前端开发如何知道用户在页面上操作行为是否符合预期?用户点击某个按钮或使用某个功能异常时我们能否快速定位?上线的功能是否会导致线上 bug? 曾经一度这些问题深深困扰我们,作为一个没有测试团队的自研型产品研发团队,我们的上线依靠发布前走查关键测试用例来避免线上问题,但这种方式耗时耗力不说,因为人为测试总有遗漏的地方,也不能保证 100% 稳定可靠,只能保证核心功能不出问题。
因此,我们需要一套可靠的前端日志系统,来帮助我们实时观测用户使用数据及线上异常情况,另可以快速定位问题,不至于出现问题还需要跟用户远程复现(效率太低)。我们把技术方案瞄准为 ELK 套件架构来帮助解决以下问题:
- 全链路问题排查,通过日志搜索查询用户的入参出参报错等全链路信息、按时间序列分析或还原用户的操作行为排查问题
- 数据统计分析,通过日志数据可以灵活的自定义统计分析,如系统的UV、PV、用户行为分析、接口调用量、接口响应速度、异常报错统计等等
- 自定义上报,因前端无法直接打印日志到服务器或数据库中,需要满足前端的一些浏览点击、资源加载、js报错、自定义上报等场景日志等需求
- 智能归因分析,监控报警需要做好报警的收敛和治理,如何使用AIGC技术去做智能化的报警分析是非常值得探索的方向
- 持久化存储,一些数据统计分析需求需要部分日志持久化存储,自行控制日志的生命周期。
系统架构
整体的系统架构采用的就是经典的ELK架构,即 Elasticsearch + Logstash + Kibana 的组合,同时引入了filebeat作为轻量化的nginx日志采集的组件。
整体的系统架构如下:
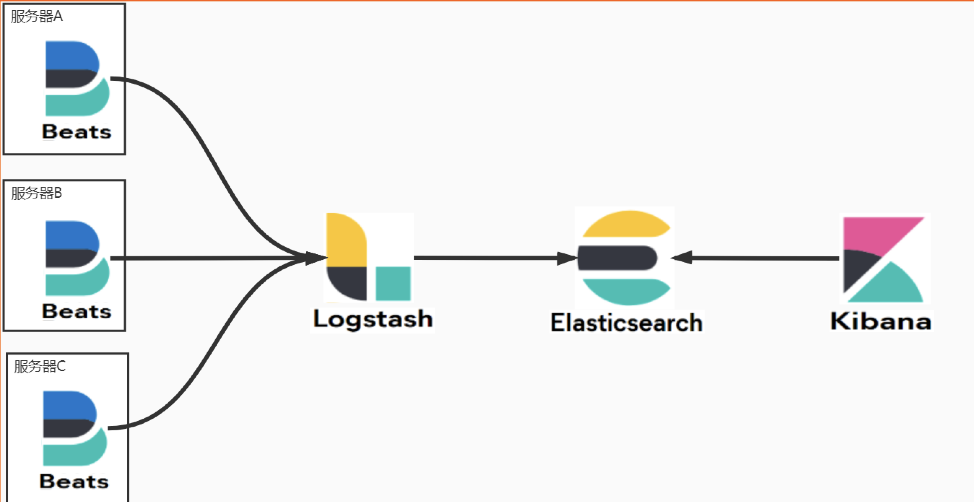
整体的方案是借助ELK架构去收集前端服务器的nginx日志及后端日志进行结构化存储到ES集群,通过ES强大的全文搜索能力及Kibana组件数据可视化能力进行日志的搜索和分析。
nginx服务器
前端服务主要使用的就是nginx进行页面部署和一些接口的代理转发,nginx日志本身就会记录用户所有的接口请求,但是nginx日志默认是不能记录到请求的响应值的和做一些前端自定义上报日志记录的,所以我们需要对nginx进行一些配置个改造。
为了能打印到接口的响应值,我们引入了OpenResty替代nginx,使用OpenResty结合lua脚本就可以非常简单的获取到接口的返回值并打印到nginx的access日志里,主要是获取接口的返回buffered并使用zlib库进行解码。
下面是nginx配置文件的简单示例,可以根据自己业务需求获取及打印所需字段:
log_format main escape=json '{"user":"$user","uri":"$uri","$http_appkey","req_body","resp_body":"$resp_body","timestamp":"$time_iso8601","ups_res_time":"$upstream_response_time"}';
location /api/ {
proxy_pass http://api.xxxx.jd.com/;
body_filter_by_lua '
local zlib = require("zlib")
if type(ngx.arg[1]) == "string" then
local resp_body = string.sub(ngx.arg[1], 1, 5000000)
ngx.ctx.buffered = (ngx.ctx.buffered or "") .. resp_body
if ngx.arg[2] then
local inflate = zlib.inflate()
local ok, decoded = pcall(inflate, ngx.ctx.buffered)
ngx.var.resp_body = ok and decoded or ngx.ctx.buffered
end
else
ngx.var.resp_body = ""
end
';
}
为了实现前端可以自定义上报一些报警日志到nginx,我们采用的是构造一些约定的请求和对应的nginx日志字段,前段需要上报日志的时候去发起请求并把上报内容放到请求体,nginx端将其写入nginx日志即可完成对应的流程。
统一封装前端SDK,将不同类型的上报约定为不同的接口,如定义一个/log的一个请求,并在nginx定义该接口返回成功状态码200,前端需要上报日志数据的时候,只需要调用SDK的方法并触发请求这个请求即可。
因为有约定的接口路径,后续进行再日志收集和处理中即对该接口做对应的数据结构化存储,实现最终的一个自定义上报数据的需求。
Filebeat组件
由于我们前端nginx部署使用的我们自已定制的基础镜像,所以可视非常方便的去做一些nginx的配置和一些组件的安装,这里我们采用的是Filebeat组件进行nginx日志的收集。
首先在基础镜像里集成Filebeat组件,以便可以再应用镜像里直接使用,然后在项目里暴露Filebeat的配置文件以及在dockerfile中添加启动Filebeat命令,下面是示例配置:
filebeat.inputs:
- type: log
paths:
- /export/access_80.log*
json.keys_under_root: true
json.add_error_key: true
json.message_key: uri
include_lines:
[
'/feedback',
'/ping',
'/api',
'/point',
'/log-reporting'
]
exclude_lines: ['/api/xxxxxx', '/fn-service/xxxxxx']
fields_under_root: true
json.overwrite_keys: true
- type: log
paths:
- /export/error.log*
output.logstash:
hosts: ['logstash.jd.local:2000']
logging:
files:
path: /export/filebeat
name: myfilebeat.log
keepfiles: 7
permissions: 0644
Logstash组件
Logstash组件主要是将多个容器的Filebeat采集数据进行统一的转换处理,如上文提到的针对不同的接口路径对数据进行结构化转换、统一的对一些不需要字段进行丢弃、提取保留接口相应的的traceId等
通过Logstash的转换处理,将不同的数据传输写入到ES集群的不同索引,最终实现日志的索引存储,以下是一个将单条日志直接写入ES的示例:
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
filter {
json {
source => "message[data]"
}
mutate {
convert => {
"ups_res_time" => "float"
}
}
prune {
whitelist_names => ["timestamp","user", "domain","uri","ip","referer","args", "resp_body","ups_res_time","ups_status"]
}
}
output {
elasticsearch {
hosts => ["http://xxxxxxx.jd.com:40000"]
index => "access_log"
user => "test"
password => "test"
}
}
Kibana可视化
经过以上的数据采集组件的层层处理,海量的日志数据已经存储到了ES集群,接下来就需要 Kibana 组件进行数据的快速搜索和可视化分析。
直接下载对应ES版本的 Kibana 程序,配置好ES集群的一些连接串信息和其他配置就可以直接部署后访问了。
Kibana 面板功能强大,我们可以基于自己业务的诉求定制面板。
traceID
在服务端我们通常通过 traceID 来做连路追踪,前端我们也可以借此思路,在用户打开平台时候通过 md5 等哈希算法生成一个 traceID,上报 traceID 来追踪用户在页面的操作路径。当然你可能会觉得都有用户 ID呢,为啥还需要 traceID,但非登录用户也需要考虑,那何不更通用一点。
总结
ELK 是当下比较成熟的日志套件,未来我们希望能够把 sentry 的一部分功能也结合进来,打造更贴合前端使用的监控平台。