最近公司的项目已经把很多之前用 tool 实现的东西改成了 skills,但这些实现并不包含脚本逻辑这一块,主要以 prompt 为主。
趁着这两天休息花一点时间深入研究了 ClawHub 上 WeChat 相关 skills 的实现方式,又自己从零做了一套“微信公众号搜索 + 文章抓取转 Markdown”的 skill。
在 openclaw 中调用我的 skill:

一开始,我以为这件事的重点是

但做到后面,我越来越确定一件事:
开发一个好 skill,难点从来不在功能本身,而在于你是否真正理解了 skill 这种交付形态。
它不是普通项目,不是单纯脚本,也不是一段 prompt。
它是一个面向 agent 的“可执行能力包”。
一、最大的误解:Skill 不就是“脚本 + 文档”吗?
刚开始接触 skill 的时候,很多人都会有一个很自然的想法:
“这不就是把一个脚本放进目录里,再写个 SKILL.md 吗?”
表面看,确实像。
一个典型的 skill 目录可能就是这样:
wechat-super-power/
├── SKILL.md
├── agents/
│ └── openai.yaml
├── references/
│ └── implementation-plan.md
└── scripts/
├── search_wechat.js
├── fetch_wechat_article.js
└── skill-entry.js
如果只看文件结构,你很容易把它理解成一个迷你项目。
但当我真的把它跑起来,尤其是把它安装到 skills 目录、让 agent 去触发时,我才发现:
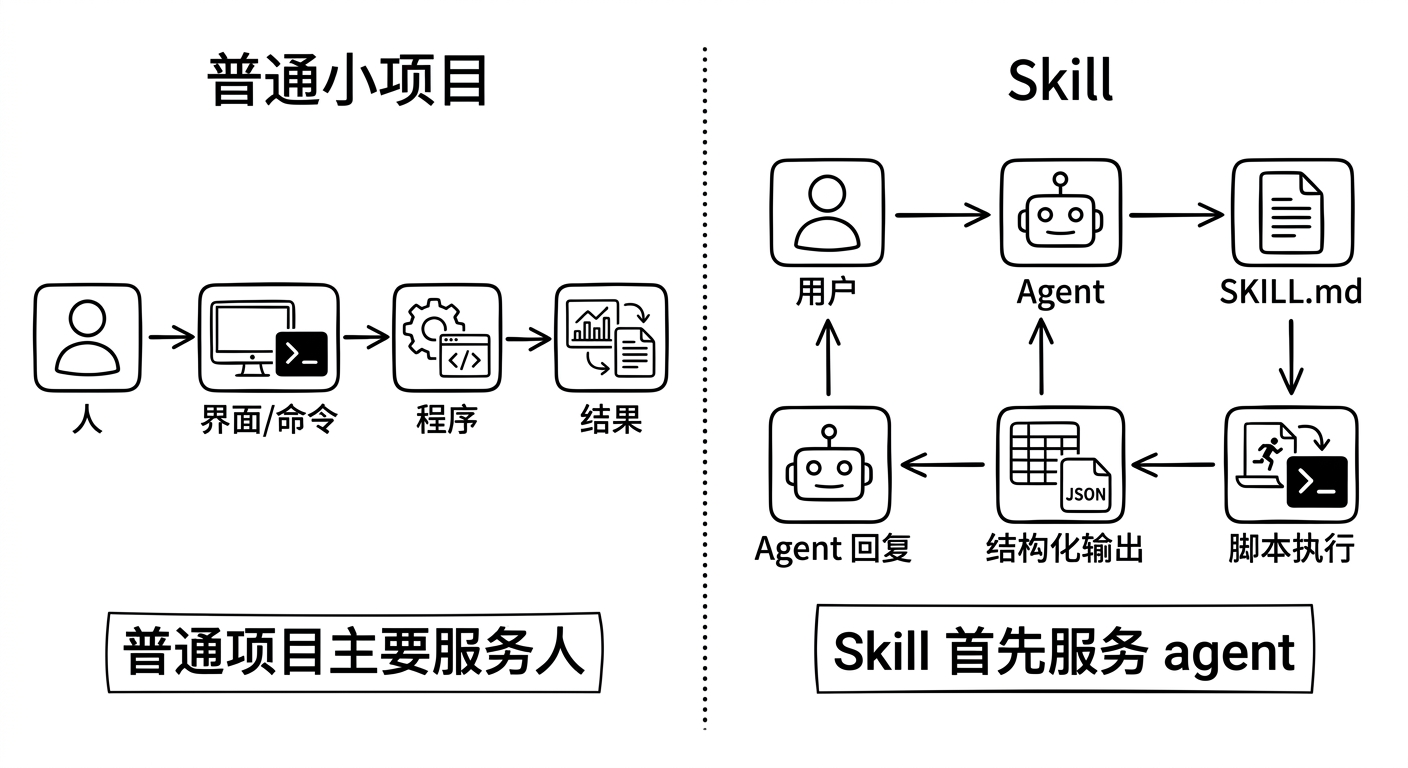
skill 和普通项目最大的区别,不在代码,而在“谁是第一使用者”。
普通项目的第一使用者是人。
Skill 的第一使用者,其实是 agent。
这意味着你开发 skill 时,首先要回答的不是:
- 我支持多少功能?
- 我用了什么技术栈?
- 我解析得够不够优雅?
而是下面这些问题:
- 模型什么时候该想到用你?
- 模型触发你之后,到底该执行哪个命令?
- 你的输出是不是稳定到可以被下一步程序继续消费?
- 如果失败了,模型能不能知道是哪里失败,而不是开始瞎猜?
- 这个目录拷到另一个环境里,是不是还能跑?
当我把这些问题真正摆到桌面上时,我才意识到:
skill 不是“小应用”,而是“给 agent 用的能力接口”。
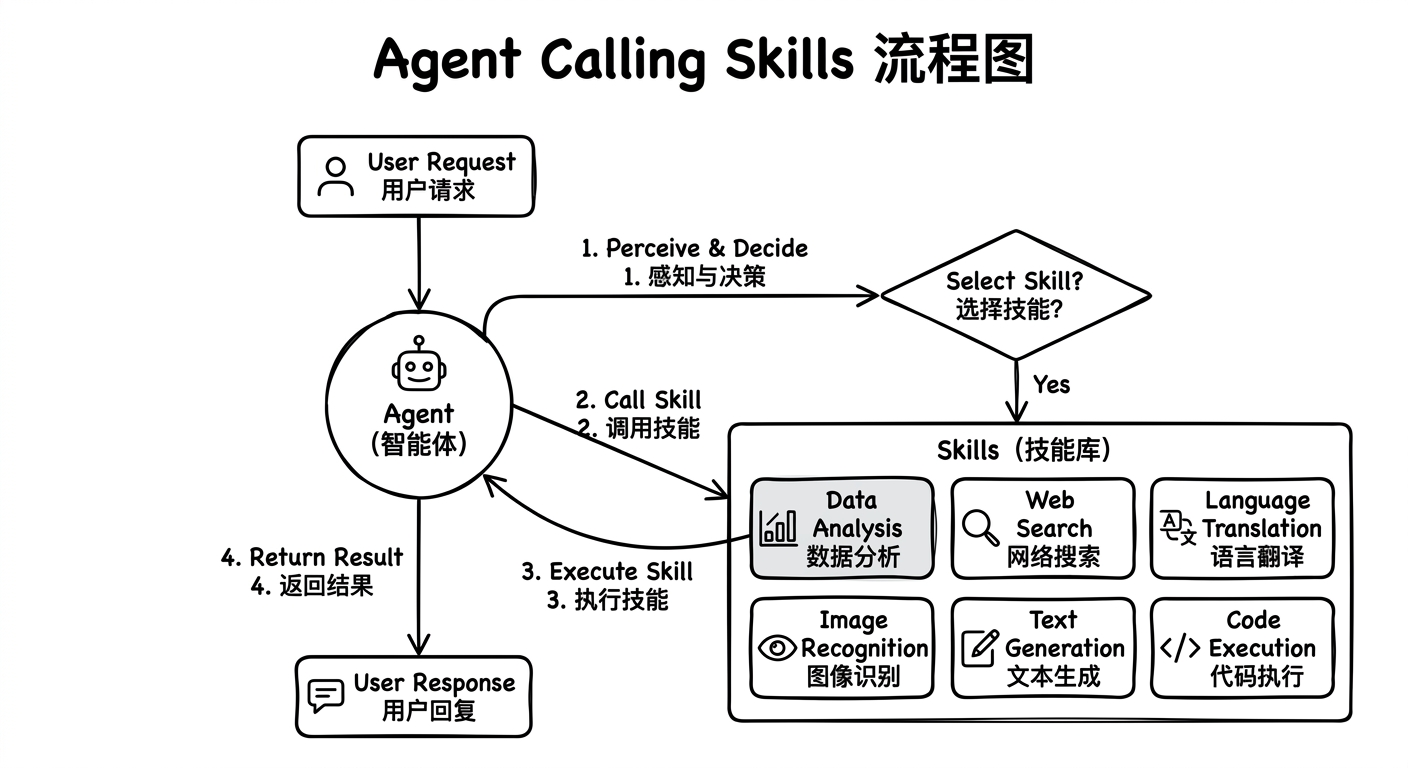
二、为什么很多 skill 看起来能跑,实际并不好用?
这是我这次感触特别深的一件事。
很多 skill,初看都挺像回事:
- 有代码
- 有目录
- 有文档
- 功能描述也挺完整
但一放进真实的 agent 环境里,问题马上就来了:
- 什么时候触发,不清楚
- 该跑哪个脚本,不清楚
- 参数怎么传,不清楚
- 返回结果长什么样,不稳定
- 有时输出 JSON,有时夹一堆日志
- 换台机器就缺依赖
- 一失败就只说一句“抓取失败”
这种 skill 最大的问题不是“不能跑”,而是“不能稳定地被 agent 使用”。
它可能对作者自己很好用,因为作者知道每个脚本是干嘛的,知道什么参数该怎么传,也知道失败时大概是什么原因。
但对于 agent 来说,这些都不是默认知识。
一个 skill 的专业度,不取决于作者懂多少,而取决于作者有没有把这些知识变成“运行时可执行的约束”。
这就是为什么我后来越来越认同一个判断:
好的 skill,不是功能最多的那个,而是让模型最少犯错的那个。
三、我真正看明白的第一件事:一个好 skill,先要把“触发条件”说清楚
以前写工具说明时,我们很容易写成:
- 这个工具可以搜索微信文章
- 这个工具可以抓取正文
- 这个工具可以转 Markdown
这些话都没错,但它们对 agent 来说其实不够。
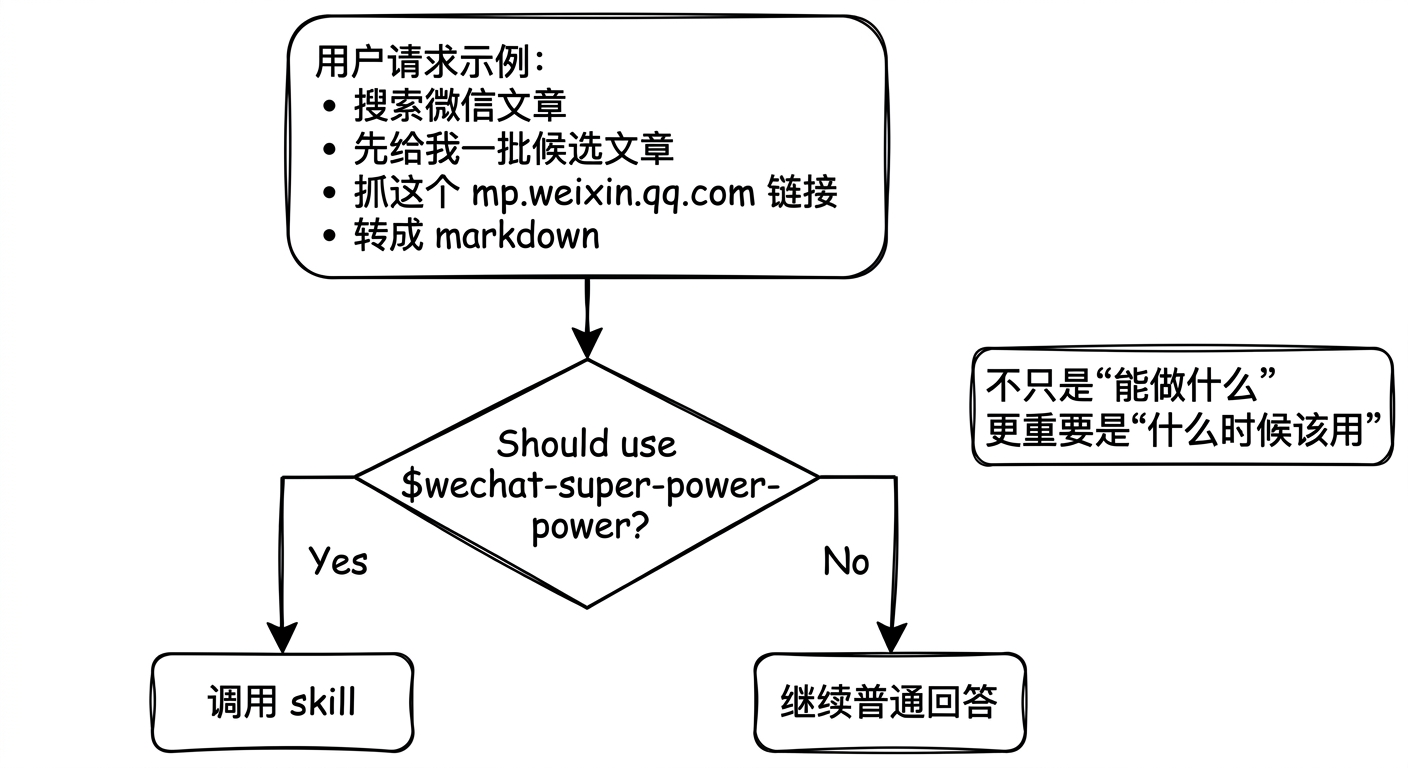
因为 agent 并不只是要知道“你能做什么”,它更需要知道“什么时候应该来找你”。
所以后来我把 skill 的触发语义明确写成这种形式:
- 当用户要按关键词搜索微信公众号文章时使用
- 当用户要先拿文章候选列表,再决定抓哪一篇时使用
- 当用户给了
mp.weixin.qq.com链接,希望提取正文并转成 Markdown 时使用 - 当用户提到“微信公众号”“微信文章”“转 markdown”时使用
看起来只是文案细化了一点,但实际效果完全不同。
前一种写法是 capability-oriented,只在描述能力。
后一种写法是 trigger-oriented,在定义触发边界。
这两者的差别非常大。
因为对于 agent 来说,最难的往往不是执行,而是在成百上千个可能能力里,什么时候想起你。
如果触发条件写得含糊,skill 再强都可能被忽略。
如果触发条件写得清晰,模型就更容易稳定调用它。
所以我现在非常认同一个经验:
写 skill 时,不要只写“我能做什么”,更要写“什么时候该找我”。
四、一个好 skill,执行路径必须“唯一”
这是我自己在做 WeChat skill 时踩过的一个坑。
一开始目录里有几个脚本:
search_wechat.jsfetch_wechat_article.jsskill-entry.js
从开发者角度看,这种结构很合理:
- 底层脚本各管一件事
- 统一入口负责分发动作
但问题在于,agent 看到后不一定会这么理解。
如果 SKILL.md 没写清楚,它可能会:
- 直接调用底层脚本
- 自己猜参数格式
- 绕过统一输出层
- 对着多个文件来回试探
而一旦发生这种“自由发挥”,稳定性就会迅速下降。
于是后来我把 SKILL.md 彻底改成了操作型说明,直接写死:
搜索时运行:
node scripts/skill-entry.js search "<关键词>" --limit <数量>
抓取时运行:
node scripts/skill-entry.js fetch "<文章链接>"
这个改动看起来很朴素,但我认为它是 skill 设计里最重要的部分之一。
因为它解决了一个本质问题:
让 agent 不需要自己决定“怎么调用”,而只需要决定“该不该调用”。
我后来越来越觉得,skill 的最佳状态就是这样:
- 模型负责判断时机
- skill 负责提供唯一执行路径
只要这两层边界清楚,整体稳定性就会高很多。
五、输出如果不稳定,再强的功能也白搭
这一点非常值得单独讲。
很多脚本作者都习惯在命令行里输出自己看着舒服的内容,比如:
- 先打印一段日志
- 中间再加点调试信息
- 最后再吐一个对象
- 出错时顺手加几句提示
人自己用时,这样问题不大。
但在 skill 里,这几乎等于埋雷。
因为 agent 不是人在看,它通常需要对输出继续做消费、抽取字段、拼接后续动作。
这时候,最重要的不是“输出丰富”,而是“输出稳定”。
所以我后来把搜索结果收敛成固定 JSON:
{
"action": "search",
"keyword": "人工智能",
"total": 5,
"items": [
{
"title": "文章标题",
"summary": "文章摘要",
"account_name": "公众号名",
"publish_time": "2026-04-05 10:00:00",
"url": "https://..."
}
]
}
抓取结果也统一成:
{
"action": "fetch",
"title": "文章标题",
"author": "公众号或作者",
"publish_time": "2026-04-05 10:00:00",
"source_url": "https://mp.weixin.qq.com/...",
"markdown": "# 标题\n\n正文"
}
这样做之后,整个 skill 的感觉一下就不一样了。
因为它不再是“一个会打印内容的脚本”,而变成了“一个有契约的能力接口”。
我现在越来越相信一句话:
对于 skill 而言,输出结构就是 API。
功能写得再漂亮,如果输出不稳定,agent 一样很难可靠地用下去。
六、真正专业的 skill,不是“永远成功”,而是“失败时也很诚实”
做微信文章抓取时,我很快就碰到一个现实问题:
很多微信文章,不是你想抓就能抓的。
会遇到这些情况:
- 搜狗中转链接被反爬拦截
- 微信正文页跳验证码
- 当前环境无权限查看
- 页面结构变化导致正文抽取失败
- 转 Markdown 后内容为空
这个时候,一个不成熟的 skill 往往会做两件危险的事:
- 出错时只说一句“失败了”
- 更糟的是,失败了还假装自己成功,输出一段并不可靠的内容
这两种都很糟。
因为 skill 不是 demo,不是表演“我大概可以”;skill 是要进入真实调用链的。
如果你失败时不清楚,调用方就没法判断下一步怎么办。
如果你失败时还假装成功,那就是直接污染后续结果。
所以我后来专门保留了这些错误语义:
- `Unsupported URL host, expected mp.weixin.qq.com or weixin.sogou.com`
- `Sogou antispider blocked URL resolution`
- `Article requires WeChat captcha verification`
- `Article content was empty after Markdown conversion`
这些错误的价值,不在于“报错写得专业”,而在于它们足够诚实。
它们告诉 agent:
- 不是所有文章都能抓
- 失败是正常情况
- 失败的原因可以被区分
- 不能因为想显得智能,就假装抓到了
这件事对我触动很大。
因为它让我意识到:
一个好 skill 的目标,不是追求 100% 成功,而是做到“成功时可信,失败时可解释”。
七、我为什么后来坚持把这个 skill 改成零依赖?
这件事非常关键。
最开始我们其实也走过“正常 Node 项目”的路子。
比如为了方便解析 HTML,用 cheerio 是很自然的选择。
在本地开发环境里,这几乎没什么问题。
但当你真正把 skill 当成一种“可分发能力包”去看时,问题立刻出现了:
- skill 要不要带
package.json? - 目标环境会不会自动
npm install? - 没装依赖的时候 runtime 会不会帮你兜底?
- 换一台机器,锁文件版本还一致吗?
- 网络受限时,依赖装不上怎么办?
这些问题,在普通项目里都可以慢慢解决;
但在 skill 里,它们会直接伤害可移植性。
于是我后来做了一个重要决定:
尽量把 skill 改成零依赖。
最终现在这个 WeChat skill 只依赖 Node.js 自带模块:
httpszlib
也就是说,它不再需要:
package.jsonpackage-lock.jsonnode_modules
这样一来,它的分发方式就变得非常简单:
- 直接把目录拷进
~/.agents/skills/ - 不需要安装依赖
- 不需要跑构建
- 只要环境里有
node就能执行
这个改动让我彻底想明白了一件事:
对 skill 这种交付形态来说,“可迁移”比“开发时舒服”更重要。
能零依赖,就尽量零依赖。
如果非要带依赖,再去考虑 Bun 打包、vendor 化、单文件分发这些方案。
但第一选择,永远是让 skill 尽可能轻。
八、为什么我后来认为 SKILL.md 不是“说明文档”,而是“运行时接口”
这是我看源码之后最深的感受之一。
以前我总觉得代码是核心,文档只是辅助。
但 skill 场景里,这个关系几乎是反过来的。
代码当然重要,但对于 agent 来说,它首先不会去“理解全部源码逻辑”。
它更依赖的是 skill 暴露出来的行为描述。
所以在我后来的版本里,SKILL.md 不再是那种泛泛的 README,而变成了真正的“操作规约”:
- 什么情况下应该触发
- 触发后执行哪个命令
- 参数怎么传
- 输出结构长什么样
- 出错时怎么理解
- 优先返回哪些字段
- 哪个脚本是统一入口,哪个只是底层实现
一旦这些信息写清楚,skill 的稳定性就大幅提升。
因为 agent 不再需要猜。
而 skill 系统里,最怕的就是“靠猜”。
所以如果今天让我给 skill 开发提一个最重要的建议,我会说:
请把 SKILL.md 当成接口设计文档来写,而不是项目介绍页。
这件事真的会改变整个 skill 的质量。
九、功能边界越小,skill 反而越强
很多人做 skill 时,很容易有一种冲动:
既然都做微信文章了,那不如顺便:
- 搜索
- 抓取
- 去重
- 摘要
- 标签分类
- 公众号画像
- 批量归档
- 洗稿
听上去很强,但实际很容易变成一个“大而虚”的东西。
我这次反而越来越认同一种相反的策略:
先把边界收紧。
比如我们这个 skill,现在就只做两件事:
- 搜索微信公众号文章列表
- 抓取文章正文并输出 Markdown
这两个能力本身就已经足够明确,而且彼此闭环:
- 搜索拿列表
- 选择链接
- 抓取正文
- 输出可消费内容
边界一旦清楚,很多事情都会跟着变简单:
- Trigger 更容易写清楚
- 执行路径更容易唯一
- 输出结构更容易统一
- 测试更容易做
- 错误语义更容易收敛
一个 skill 如果一开始就想做成平台,最后往往每个能力都不够稳。
但如果先把一个小闭环做扎实,它反而更像一个真正可用的模块。
所以我的经验是:
好 skill 不是“大而全”,而是“小而硬”。
十、如果让我重新总结“如何开发好一个 skill”,我会给出这 8 条原则
做完这套 WeChat skill 之后,如果让我用最精炼的方式总结,我会写成下面这 8 条:
1. Skill 首先服务的是 agent,不是开发者自己
你自己觉得好用,不代表 agent 就能稳定调用。
2. 先定义触发条件,再写功能
什么时候用你,比你能做什么更重要。
3. 执行路径必须唯一
能统一入口就统一入口,不要让 agent 自己猜该跑哪个脚本。
4. 输出结构必须稳定
脚本打印内容不是重点,重点是输出能不能被继续消费。
5. 错误必须诚实
失败不是问题,假装成功才是问题。
6. 零依赖优先
skill 越轻,越容易安装、复制、复用。
7. SKILL.md 是运行时接口
不要把它写成 README 式宣传文档。
8. 边界要小而清晰
一个 skill 做好一个闭环,胜过做十个半成品能力。
这 8 条听起来不华丽,但我现在越来越相信:
它们几乎决定了一个 skill 是不是“能长期活下去”。
最后:开发一个好 skill,本质上是在设计“可被模型稳定调用的能力”
一个好 skill,核心从来不是“功能多强”,而是“是否能被稳定地用起来”。
这句话听上去很朴素,但我现在觉得,它值得每一个正在做 skill 的人,反复想一想。
开源下我的 skills: https://github.com/jacoobwang/wechat-super-power